Käyttäytymistieteet pyrkivät selittämään ja ennustamaan käyttäytymistä. Nykyisin käyttäytymisen tutkimuksessa painottuu selittäminen ja teoreettisten mallien rakentaminen. Ne pohjautuvat pääosin laboratoriotutkimuksiin ja tilastollisiin menetelmiin. Ongelmana on kuitenkin se, etteivät niiden tulokset ole helposti sovellettavissa reaalimaailmaan. Tekoälyn ja aivotutkimuksen kehittyminen on johtanut mielenkiintoisiin mahdollisuuksiin käyttäytymisen mallintamisessa ja ennustamisessa. Artikkeli on yhteenveto projektien NeuroService (TEKES) ja Tekoäly viestin luotettavuuden arvioitsijana (Helsingin Sanomain Säätiö) tuloksista.
Klassiset laboratoriokokeet ja kvantitatiiviset tutkimusmenetelmät
Kun tutkitaan ihmisen käytöstä perinteisillä kvantitatiivisilla menetelmillä, tutkittava ilmiö pyritään tuomaan esiin mahdollisimman pelkistettynä. Muuttujia karsitaan mahdollisimman paljon, jolloin parametriavaruuden dimensiosta tulee pieni. Taustalla on usein nomoteettiseen perusoletukseen, jonka mukaan ihmisaivot käyttävät suurta määrää hyvin yksinkertaisia sääntöjä – ikään kuin palapelin paloja – joiden avulla ne tulkitsevat ympäristöään. Sääntöjen löydyttyä, monimutkainenkin käyttäytyminen voidaan selittää niiden avulla. Näin perinteiset tutkimusasetelmat karsivat pois ”ylimääräiset” taustamuuttujat ja jättävät jäljelle keskeiset muuttujat, joihin käyttäytyminen oletettavasti perustuu. Lisäksi tuloksia analysoidaan monesti tilastollisilla lineaarisilla menetelmillä. Tähän lähestymistapaan liittyy kuitenkin vakavia rajoituksia.
Litteän maan harha
Tutkimustulosten sovellettavuuden ongelma korostuu, kun uusia laboratoriokokeita ja teoreettisia malleja tehdään entisten, pelkistettyjen kokeiden pohjalta. Tällöin on vaarana ajautua teoreettiseen umpikujaan ja toistettavuuskriisiin, jolloin havaintoja on yhä vaikeampi yhdistää todellisen maailman kanssa. Toisin kuin laboratoriokokeet, jotka vastaavat rajattuihin kysymyksiin vain kourallisella muuttujia, aivot osaavat toimia moniulotteisessa ympäristössä. Tästä syntyy jännite tutkimuksellisen kontrollin ja tulosten sovellettavuuden välillä, kun reaalimaailma ei noudata laboratoriokokeiden lainalaisuuksia ja oletuksia. Reaalimaailma on yleensä epälineaarinen ja moniulotteinen. Lisäksi se on vahvasti aikariippuva ja muuttujien välillä on hankalasti ennakoitavia yhteyksiä.
Käyttäytymisen tutkimuksessa tulee katsoa syötteen (ärsyke) ja vasteen (tulos) välistä kuvausta moniulotteisena prosessina. Jos tutkijan valinnat kutistavat prosessin parametriavaruutta liikaa, tämä voi johtaa ns. litteän maan harhaan (eng. flatland fallacy). Tämä helpottaa tutkimuksen tekemistä, mutta samalla kadottaa oleellisia muuttujia ja vuorovaikutuksia, joita ei osata ennakoida. Kuvitellaan, että tutkija haluaa selvittää, mitkä tekijät vaikuttavat hyödykkeen X ostamiseen lähikaupasta. Kuluttajan päätökseen vaikuttaa ainakin tuotteen X hinta, sen saatavuus ja sen tarpeellisuus (3 ulottuvuutta). Toisaalta päätökseen voi vaikuttaa myös kellonaika, vuodenaika, kuluttajan varallisuus, kilpailevien tuotteiden tarjonta ja niin edelleen. Eli todellisia ostopäätökseen vaikuttavia tekijöitä on valtavasti ja ne voivat helposti jäädä huomaamatta. Kuitenkin perinteinen kuluttajatutkimus keskittyy yleensä vain muutamaan ostamiseen vaikuttavaan muuttujaan kerrallaan.
Kuvio 1 havainnollistaa ilmiötä. Siinä esitetään 1000 kuvitteellisen tuotteen hankintaprosessi, jossa lopullinen ostopäätös riippuu vain hinnasta, saatavuudesta ja tarpeellisuudesta. Jos prosessista mitataan vain kaksi ensimmäistä muuttujaa, saatavuuden ja hinnan välinen syy-yhteys on epäselvä ja tuloksien tulkinta on hankalaa. Vain mittaamalla kaikki kolme muuttujaa, tulos on selkeä ja päätöspinnan kolmiulotteinen muoto tulee esiin. Sama analogia pätee, kun muuttujia on enemmän, esim. satoja tai tuhansia.
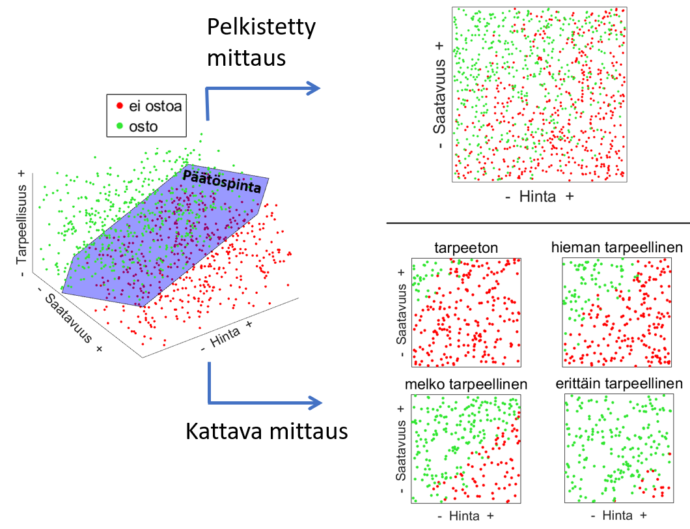 Kuvio 1. Havainnekuva ostopäätöksen tekemisestä kuvitteellisessa kolmen muuttujan mallissa. Pelkistetyllä, kahden muuttujan mittauksella (saatavuus ja hinta) alkuperäisen kolmiulotteisen päätöspinnan muoto jää epäselväksi ja tuloksien tulkinta on hankalaa, koska eri lopputulokset sekoittuvat. Vain kattava mittaus, jossa myös tarpeellisuus on mukana, tuottaa oikean kuvan prosessista.
Kuvio 1. Havainnekuva ostopäätöksen tekemisestä kuvitteellisessa kolmen muuttujan mallissa. Pelkistetyllä, kahden muuttujan mittauksella (saatavuus ja hinta) alkuperäisen kolmiulotteisen päätöspinnan muoto jää epäselväksi ja tuloksien tulkinta on hankalaa, koska eri lopputulokset sekoittuvat. Vain kattava mittaus, jossa myös tarpeellisuus on mukana, tuottaa oikean kuvan prosessista.
Historiallisena esimerkkinä voidaan mainita näköaivokuoren neurotieteellinen tutkimus, jossa rajoituttiin pitkään ärsykkeisiin, jotka sisälsivät erilaisia yksinkertaisia geometrisia kuvioita. Eläinkokeissa mittauksia tehtiin yleensä kerrallaan yksittäisistä hermosoluista. Näin selvitettiin hyvin näköaivokuoren toimintamekanismeja. Vähitellen alettiin käyttää luonnollisia ärsykkeitä, kuten videoita ja virtuaaliympäristöjä, sekä kehittyneempiä mittausmenetelmiä (kymmeniä tai satoja hermosoluja). Tällöin huomattiin, että vanhat tulokset eivät yleistyneet ja mallien selitysaste jäi alle 20 prosentin. Näköaistin toimintaa ei voitukaan selittää yksinkertaistettujen ärsykkeiden ja matalaulotteisten mittausten pohjalta tehtyjen mallien perusteella. Nykyisin tiedämme, että aivojen toiminta (näköaivokuori mukaan lukien) pohjautuu moniulotteiseen dynaamiseen prosessiin, joka muodostuu miljardien aivosolujen synkronoidusta aktivaatiosta eräänlaisilla hyperpinnoilla (vrt. kuvan 1 päätöspinta). Aivojen ja käyttäytymisen toiminnan ymmärtämien vaatii moniulotteista lähestymistapaa.
Tekoäly, luonnolliset ärsykkeet ja käyttäytymisen ennustaminen
Edellä mainittuja ongelmia voidaan vähentää soveltamalla tekoälytutkimuksen menetelmiä ja luonnollisia ärsykkeitä. Tekoäly on laaja kattotermi menetelmille, joilla pyritään tuottamaan älyä, kuten loogista päättelyä ja luovuutta. Tutkimuspuolella käytetään useimmin termiä koneoppiminen, joka käsittää algoritmeja (esim. neuroverkot) ja käytäntöjä (esim. ristiinvalidointi), joita tekoälyn kehityksessä tarvitaan. Tekoälysovelluksissa tavoitteena on löytää – yleensä epälineaarinen – malli, joka mukautuu opetusdataan ja osaa tehdä tarkkoja ennusteita.
Litteän maan harhaan, perinteisten tutkimusten heikkoon ennustekykyyn ja tulosten toistettavuuteen on havahduttu etenkin neurotieteissä. Niissä on jo pitkään hyödynnetty luonnollisia ärsykkeitä, koneoppimismalleja sekä aivokuvantamismenetelmiä (esim. toiminnallinen magneettikuvaus fMRI), jotka mittaavat ärsykkeiden tuottamia aivojen aktivaatioita. Tällöin sekä ärsykkeet että vasteet ovat korkeaulotteisia. Vasteet sisältävät havaitun käyttäytymisen lisäksi myös ennen päätöksen muodostumista tapahtuvat aivosignaalit. Esimerkiksi fMRI:n tapauksessa tämä voi tarkoittaa esim. 100.000 signaalia yhden valintatilanteen yhteydessä.
Tuoreet tutkimukset ovat osoittaneet, että aivosignaaleista mitattua dataa ja koneoppimismenetelmiä yhdistämällä voidaan ennustaa aitoa kulutuskäyttäytymistä paremmin kuin perinteisillä kysely ja haastattelumenetelmillä. Kuluttajatutkimus ja markkinointi odottavat tältä neuroennustamismenetelmältä (neuroforecasting) paljon tulevina vuosina. Esimerkiksi Stanfordin yliopiston tutkimuksessa 30 nuorelle näytettiin joukkorahoitusmainoksia yksi kerrallaan samalla kun heidän aivoaktivaatioiden muutoksia mitattiin fMRI:n avulla. Kokeessa nuoret päättivät, rahoittavatko kyseisiä joukkorahoituskampanjoita vai eivät. Joukkorahoitusmainokset olivat aitoja, sillä ne julkaistiin suurelle yleisölle tutkimuksen jälkeen. Kokeen jälkeen osallistujille annettiin rahaa ja mahdollisuus sijoittaa haluamaansa kohteeseen. Ilmeni, että niihin joukkorahoituskampanjoihin sijoitettiin eniten, joiden mainokset aktivoivat henkilön etuotsalohkon keskialueita ja aivojuoviota. Kun joukkorahoituskampanjat julkaistiin Internetissä, ilmeni, että tämän pienen ryhmän keskimääräinen aivojuovioaktivaatiota hyödyntävä malli ennusti rahoituskampanjan menestymistä todellisilla markkinoilla, mutta perinteisillä menetelmillä saadut tulokset eivät.
Koneoppimisalgoritmien ja aivotutkimusten kyky ennustaa käyttäytymistä perustuu siihen, että valtaosa ihmisistä käyttäytyy keskiarvon mukaisesti. Tutkimusten seuraava askel olisi ennusteiden hienosäätäminen erilaisten ryhmien mukaan, mutta tämä vaatii myös lisää dataa. Aivokuvantamisen hyödyntämisen suurimpia esteitä ovat sen vaatimat suuret resurssit, niin taloudelliset kuin osaamiseen liittyvät. Yksinkertaisen kyselylomakkeen tekeminen ja lähettäminen hoitunee päivässä ja onnistuu jopa täysin ilmaisilla työkaluilla (esim. Google Forms), kun taas aivokuvantamisdatan keräys on viikkoja tai jopa kuukausia kestävä prosessi. Toisaalta teknologia kehittyy ja markkinoilla on jo joitakin kotikäyttöön suunniteltuja edistyneitä fNIRS- ja EEG-laitteita, joita voisi hyödyntää datan keräyksessä.
Moniulotteisen datan analyysi on haastavaa
Mitä enemmän ulottuvuuksia datassa on, sitä hankalampaa sen analyysi on. Tällöin ollaan helposti tilanteessa, jossa on enemmän parametreja kuin näytteitä, mikä on ongelmallista perinteisiä tilastollisia malleja käytettäessä. Koneoppimismenetelmät soveltuvat kuitenkin yleensä hyvin myös korkeaulotteiselle datalle. Niiden algoritmien sisään rakennetaan regularisaatiomekanismeja, joilla mallien mukautumiskykyä voidaan rajoittaa ja jättää huomiotta tarpeettomat ulottuvuudet ja välttää ylioppiminen. Mallien keskeiset parametrit säädetään ristiinvalidoinnilla ja näin maksimoidaan mallin ennustamiskyky. Toisaalta moniulotteista datan analyysi ei aina vaadi monimutkaisia menetelmiä, mikäli ongelmaa lähestyy eri tavalla. Esimerkiksi neurotieteen puolella suositussa ns. esittävässä similariteettianalyysissa (eng. representational similarity analysis) voidaan käyttää perinteistä korrelaatiota ja vertailla vasteiden samankaltaisuutta. Tällöin ei tarvitse ymmärtää moniulotteisia vasteita itsessään, vaan sen sijaan keskitytään vasteiden välisiin suhteisiin ja hypoteesien testaamiseen niiden kautta.
Resepti kohti parempia ja toistettavia tutkimuksia
Oikein käytettynä naturalistiset koeasetelmat ja perinteiset, tiukasti kontrolloidut laboratoriokokeet täydentävät toisiaan. Perinteiset kokeet ovat tärkeitä käyttäytymisilmiöiden yksityiskohtien ja niiden suurempiin kokonaisuuksiin liittyvien reunaehtojen kartoittamisessa. Usein ongelman rajaaminen on myös käytännössä välttämätöntä esimerkiksi riittävän suuren otoskoon saamiseksi. Kokeita suunniteltaessa on kuitenkin jatkuvasti pidettävä mielessä tulosten yleistyminen todelliseen maailmaan. Voimme tiivistää ajatuksemme muutamaksi yleisohjeeksi, jotka kannattaa huomioida tutkimuksia suunniteltaessa ja toteuttaessa [mukaillen Jolly & Chang, 2019, Koul et al. 2018 ja Nastase et al. 2020]:
- Hypoteesit kannattaa tehdä reaalimaailman näkökulmasta, eli pohtia ilmiöitä ja käyttäytymistä, joka tapahtuu luonnollisessa ympäristössä.
- Data-avaruutta ei pitäisi rajoittaa voimakkaasti etukäteen, eli datan keräys pitäisi toteuttaa aina mahdollisimman lähellä aitoa ympäristöä/ilmiötä ja datan keräyksen on oltava kattavaa; mieluummin liikaa dataa, kuin liian vähän. Koeasetelmaa kannattaa manipuloida vain siltä osin, kun se on ekologisesta näkökulmasta realistista ja noudattaa tutkitun ilmiön luonnollisia rajoituksia.
- Kehitettyjen laskennallisten mallien yleistyvyys kannattaa aina testata datalla, joka ei ole ollut mukana mallin kehityksessä. Tämä on paras tapa varmistaa, että malli ei ole liian yksinkertainen tai tarpeettoman monimutkainen.
- Tilastollisissa analyyseissa kannattaa suosia moderneja, bayesilaisia menetelmiä, joissa yhdistyvät tilastotieteen ja koneoppimisen parhaat puolet, eli todennäköisyyslaskenta ja mallien hyvä yleistettävyys.
Lähteet:
- Jolly, E., & Chang, L. J. 2019. The Flatland Fallacy: Moving Beyond Low–Dimensional Thinking. Topics in Cognitive Science, 11(2), 433–454. https://doi.org/10.1111/tops.12404
- Koul, A., Becchio, C., & Cavallo, A. 2018. Cross-validation approaches for replicability in psychology. Frontiers in Psychology, 9(JUL), 1–4. https://doi.org/10.3389/fpsyg.2018.01117
- Nastase, S. A., Goldstein, A., & Hasson, U. 2020. Keep it real: rethinking the primacy of experimental control in cognitive neuroscience. NeuroImage, 222(August), 117254. https://doi.org/10.1016/j.neuroimage.2020.117254
- Falk, E. B., Berkman, E. T., Mann, T., Harrison, B., & Lieberman, M. D. 2010. Predicting persuasion-induced behavior change from the brain. Journal of Neuroscience, 30(25), 8421–8424. https://doi.org/10.1523/JNEUROSCI.0063-10.2010
- Yarkoni, T., & Westfall, J. 2017. Choosing Prediction Over Explanation in Psychology: Lessons From Machine Learning. Perspectives on Psychological Science, 12(6), 1100–1122. https://doi.org/10.1177/1745691617693393
- Knutson, B., & Genevsky, A. 2018. Neuroforecasting Aggregate Choice. Current Directions in Psychological Science, 27(2), 110–115. https://doi.org/10.1177/0963721417737877
- Orrù, G., Monaro, M., Conversano, C., Gemignani, A., & Sartori, G. 2020. Machine learning in psychometrics and psychological research. Frontiers in Psychology, 10(January), 1–10. https://doi.org/10.3389/fpsyg.2019.02970