Miten tekoälystä on työpajojen tukiälyksi? Työpajoissa yhteiskehitetään usein aihepiiriä kokevaa tietoa, jota fasilitaattorit tai työpajan järjestäjät analysoivat ja muokkaavat jatkotyöskentelyn tueksi. SERkut-hankkeen ekosysteemityöpajan materiaalien analysoinnissa hyödynnettiin tekoälyteknologioita. Tässä artikkelissa avataan tapoja, joilla työpajan tuotoksia analysoitiin tekoälyavusteisesti sekä pohditaan siinä havaittuja seikkoja.
 Kuva: PixieMe /Adobe Stock (Laurean Education-lisenssi)
Kuva: PixieMe /Adobe Stock (Laurean Education-lisenssi)
Laurea-ammattikorkeakoulun ja Forum Virium Helsingin SERkut – Sähkö- ja ElektroniikkalaiteRomut kiertoon uusilla toimintatavoilla -yhteishankkeen tavoitteena on tehostaa kaupungeista syntyvän sähkö- ja elektroniikkalaiteromun (SER) kierrätystä kehittämällä uusia tuote- ja palveluinnovaatioita yhteistyössä kaupunkien, yritysten ja tutkimus-, kehitys- ja innovaatiotoimijoiden kanssa. (Seppälä 2024.) Hankkeen ensimmäisessä ekosysteemityöpajassa 7.11.2024 järjestetyssä työpajassa osallistujat työstivät työpajan kahta keskeistä kysymystä:
- Mitä uusimaalaiset toimijat voivat tehdä SER-kierrätyksen ja -uusiokäytön edistämiseksi?
- Mitä haasteita ja mahdollisuuksia ryhmässä tunnistetaan uusimaalaisen SER-kierrätyksen ja -uusiokäytön edistämiseen liittyen?
Osallistujat dokumentoivat aiheita käsitelleiden keskustelujensa tuotokset kuvassa 1 nähtäville kanvaksille ja esittivät ne työpajan päätteeksi koko osallistujajoukolle. Työpajan jälkeen aloimme analysoimaan aineistoa SERkut-hankkeessa ekosysteemiasiantuntijana työskentelevän kollegani Kaisla Saastamoisen kanssa ja päätimme kokeilla ChatGPT:n maksullisen version hyödyntämistä työn tukena. Koska SERkut-hankkeen ekosysteemityön tuotoksia esitellään omissa julkaisuissaan, pureudun tässä artikkelissa nimenomaan työpajan tuotosten tekoälyavusteiseen analysointiin.
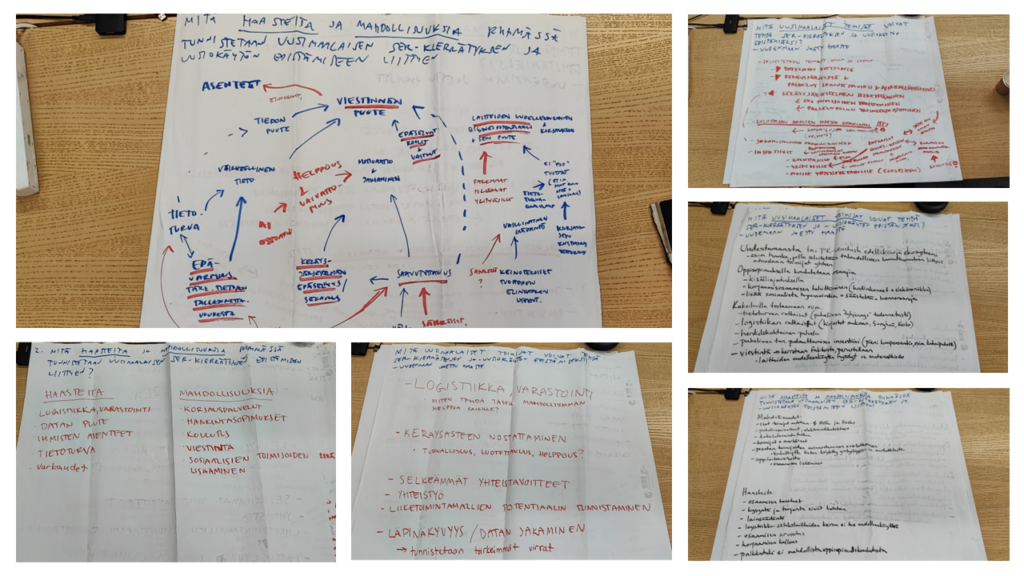 Kuva 1. Tekoälyanalyysin lähtökohtana olleet kuvat työpajassa tuotetuista kanvaksista (kuvaaja: Mikael Seppälä/Laurea-ammattikorkeakoulu).
Kuva 1. Tekoälyanalyysin lähtökohtana olleet kuvat työpajassa tuotetuista kanvaksista (kuvaaja: Mikael Seppälä/Laurea-ammattikorkeakoulu).
Tekoälyavusteisesti analysoitu ensisijainen aineisto koostui SERkut-hankkeen ekosysteemityöpajassa tuotetuista kanvas-materiaaleista. Nämä kanvas-pohjat valokuvattiin, ja kuvat toimivat tekoälyavusteisen analyysin lähtökohtana. Toissijainen aineisto koostui työpajan esityksistä tehdyn videotallenteen transkriptiosta, joka tuotettiin Microsoft Stream -videopalvelun tekoälyä hyödyntämällä. Yhdistämällä nämä kaksi aineistolähdettä saatiin kattava kuva työpajan tuloksista ja osallistujien esiin tuomista teemoista.
Analyysin tavoitteena oli jäsentää työpajassa kerätty aineisto tunnistamalla keskeiset teemat, haasteet ja mahdollisuudet SER-kierrätyksen kehittämiseksi. Tämän pohjalta luotiin selkeä kokonaiskuva nykytilanteesta sekä ehdottamaan konkreettisia toimenpiteitä ja yhteistyömalleja, jotka edistäisivät sähkö- ja elektroniikkalaitteiden kiertotaloutta kaupunkiympäristössä. (Seppälä 2024.)
Aineistojen analyysissä avustaneet tekoälytekniikat
Työpajassa tuotetut kanvas-materiaalit analysoitiin hyödyntämällä ChatGPT:n GPT-4-mallin visuaalisia ominaisuuksia, jotka mahdollistavat tekstin poimimisen kuvista optisen merkintunnistuksen (OCR, englanniksi Optical Character Recognition) tekniikkaa hyödyntämällä. OCR:n avulla koneet tunnistavat ja muuntavat kuviin tallennettua tekstiä digitaaliseksi tekstiksi. GPT-4:n kyky käsitellä sekä kuvia että tekstiä mahdollistaa kuvapohjaisten tehtävien suorittamisen, kuten tekstin poimimisen kuvista ja niiden analysoinnin. (OpenAI 2024.)
Kuvista poimitun tekstin analysoinnissa käytettiin klusterointimenetelmiä, jotka ryhmittelevät samankaltaisia tietoja yhteen. Klusterointialgoritmit, kuten K-keskiarvot ja tiheyspohjaiset menetelmät, auttavat tunnistamaan piilotettuja rakenteita datassa ja löytämään samankaltaisia piirteitä tietoryhmistä. Näiden algoritmien avulla työpajassa tuotetut ideat ja teemat voitiin ryhmitellä loogisiin kokonaisuuksiin, mikä helpotti keskeisten teemojen ja mission tunnistamista. (Winter 2024.)
Microsoft Stream hyödyntää automaattisten tekstitysten luomisessa kehittyneitä tekoälytekniikoita, erityisesti puheentunnistusta ja luonnollisen kielen käsittelyä. Microsoft Streamista sai ladattua transkription docx-tiedostomuodossa. Se lähetettiin ChatGPT:hen, jossa se analysoitiin yhtälailla hyödyntämällä klusterointia.
Minkälaisia vaiheita kuului aineistojen analysoitiin?
Tekoälyn tuottamiin analyyseihin ei kannata tukeutua täysin ja analyysien laatua saa parannettua ohjaamalla tekoälyä. Kuvaan seuraavassa vaiheita, joita käytimme työpaja-aineistojen tekoälyavusteisessa analysoimisessa.
- Kuvien tekstisisällön poiminta ja sisältöjen listaaminen
Työpajassa osallistujien tuottamat kanvakset digitoitiin työpajan jälkeen paikan päällä valokuvaamalla. Kuvat lähetettiin ChatGPT:hen visuaalista tunnistamista varten ja tunnistuksen perusteella saatiin lista kanvasten sisältämistä teksteistä.
- Listan tarkastaminen ihmisen tekemänä
Huomasimme listaa tarkistaessamme, että siinä ei ollut ihan kaikkia kanvaksissa olevia rivejä, joten emme hyväksyneet tekoälyn tuottamia sisältöjä suoraan, vaan pyysimme tekoälyä varmistamaan, että kaikki kuvista tunnistetut sisällöt löytyivät listalta. Tämän kyselyn avulla saimme laajennetun listan, jossa oli mukana myös puuttuneet sisällöt.
- Sisältöjen klusterointi
Halusimme ymmärtää analyysin avulla ryhmien tuotoksista muodostuneita kokonaisuuksia hahmottaaksemme SER-haasteen kokonaisuutta paremmin, joten pyysimme tekoälyä ryhmittelemään listan temaattisiin klustereihin. Tämä mahdollisti keskeisten teemojen ja aiheiden tunnistamisen aineistosta.
- Klusterien tarkistaminen ihmissilmin
Tarkistimme Saastamoisen kanssa syntyneet klusterit ja erityisesti, että niissä oli huomioituna kaikki ryhmän tuottamat vastaukset. Alkuperäisen listan täydentämisen jälkeen olimme tyytyväisiä syntyneistä klustereista.
- Transkription analyysi
Syntyneitä klustereita laajennettiin lähettämällä tekoälylle transkriptiotiedosto, joka sisälsi ryhmien puheenvuorot, joissa he avasivat tuottamiaan kanvaksia sekä niissä olevia ajatuksia. Tekoälyavusteisen klusteroinnin tueksi poimittiin transkriptiosta siistittyjä lainauksia, jotka selittivät, miksi ryhmät pitivät tiettyjä teemoja tärkeinä, sekä etsittiin täydentävää tietoa, joka syvensi klustereiden sisältöjä koskevaa ymmärrystä. Varsinaiset klusterit eivät päivittyneet transkription sisältöjen täydentämisen jälkeen, joten transkriptio toimi toissijaisena aineistona.
- Mission määrittely
Yksi työpajan tavoitteista oli jaetun haasteen määrittelemisen käynnistäminen. Kuvien ja transkription perusteella tekoälyä pyydettiin laatimaan missiomääritelmä, joka perustui kanvasten kysymyksiin ja heijasti työpajan osallistujien näkemyksiä. Tämä vaihe yhdisti aiemmin tunnistetut teemat selkeäksi ja yhtenäiseksi tavoitteeksi, jota työstämme edelleen SERkut-hankkeen toisessa ekosysteemityöpajassa.
- Mission Model Canvasin laatiminen
Mission määritelmän tekemisen lisäksi tekoäly jäsensi työpajan materiaalit pyytämättä Mission Model Canvasin avulla. Mission Model Canvas on bisnesmallikanvaksen sovellettu versio missiolähtöisille organisaatioille (Blank 2016). Kaikki aiemmassa vaiheessa tunnistetut klusterit huomioitiin Mission Model Canvasissa, joka kuvasi SER-mission toteuttamisen keskeisiä osa-alueita. Vaikka saimme tämän kanvaksen täytettynä pyytämättä, päätimme hyödyntää sitä jatkossakin SERkut-hankkeen ekosysteemityöpajojen materiaalien koostamisessa. Tekoälyn tarjoamasta yllätyksellisestä vastauksesta oli tässä tapauksessa hyötyä.
Tekoälyavusteisen analyysin rajoitteet
Tekoälyn avulla tehty analyysi tuo mukanaan monia etuja, kuten tehokkuuden ja mahdollisuuden käsitellä suuria määriä monenlaista dataa. Tekoälyavusteisen analyysin tekemisessä on myös rajoitteita, jotka on syytä huomioida.
GPT-4:n visuaaliset kyvyt osoittautuivat tehokkaiksi tekstin poimimisessa kuvista, mutta prosessissa havaittiin myös rajoitteita. Optinen merkintunnistus (OCR) voi toisinaan tulkita käsinkirjoitetun tekstin tai huonosti valaistujen kuvien sisältöä virheellisesti. Tämä johtaa puutteisiin tekoälyn esittämissä tiedoissa, mikä vaikuttaa analyysin kattavuuteen. Huolellinen kuvien laatuun ja tekstin selkeyteen panostaminen on olennaista luotettavan analyysin varmistamiseksi. Kuvien tunnistusta voi myös edesauttaa ohjeistamalla työpajojen osallistujia kirjoittamaan tikkukirjaimilla ja paksuilla tusseilla. Tälläinen ohjeistus oli olennaisessa roolissa SERkut-hankkeen kuva-aineiston analyysin onnistumisessa.
Työpajan videotallenteiden tekoälypohjainen transkriptio tarjosi hyvän pohjan analyysille, mutta erityisesti suomen kielen transkriptioissa on usein puutteita. Erityissanat, kuten ihmisten nimet ja vaikkapa kiertotalouden termistö, sekä monimutkaiset lauserakenteet voivat aiheuttaa virheitä tai epätarkkuuksia tekoälyn tuottamiin transkriptioihin. Tämä korostaa ihmisen tekemän tarkistuksen tarvetta, erityisesti kielellisesti monimutkaisissa aineistoissa.
SERkut-hankkeen työpajan aineiston analyysissä havaittiin, että tekoälyn tuottamat sisällöt eivät olleet suoraan käytettävissä ilman ihmisen tekemää tarkistusta ja täydentämistä. Sekä kanvasten että transkriptioiden tarkistus ihmissilmin varmisti, että analyysissä huomioitiin kaikki olennaiset yksityiskohdat ja sisältö vastasi alkuperäisiä aineistoja. Tämä ihmisen ja tekoälyn yhteistyö on olennaista takaamaan analyysin laadun ja luotettavuuden.
Vaikka tekoäly tarjoaa merkittäviä etuja analyysityössä, sen tuottamien tulosten tarkistaminen ja täydentäminen ihmisen toimesta on välttämätöntä erityisesti monitahoisissa ja kielellisesti haastavissa tapauksia. Tekoäly voi tukea ihmistä analyysityössä, mutta ei korvata sitä täysin. Soveltamamme yhteistyömalli maksimoi tekoälyn hyödyt ja minimoi siihen liittyvät riskit. Hyödynsimme tekoälyn avulla tuottamaamme analyysiä joulukuussa 2024 järjestetyn SERkut-hankkeen toisen työpajan suunnittelussa ja pidimme analyysiä onnistuneena käyttötarkoitukseemme.
Kirjoittaja
YTM, KM, KTM, MBA, Seppälä on ekosysteemien ja systeemisen innovaatiojohtamisen asiantuntija ja työskentelee SERkut-hankkeen projektipäällikkönä. Hän koordinoi Laurean innovaatiojohtamisen ja ekosysteemien teematiimin toimintaa.


Lähteet
Tämän artikkelin ensimmäinen kuva (nostokuva) ei ole CC BY-SA -lisensoitu. Sitä on käytetty Adobe Stockin Education-lisenssin ehtojen mukaisesti, eikä sitä saa käyttää edelleen ilman erillistä lupaa.